A-AFMA-Localization: Automatic amniotic fluid measurement from ultrasound images¶
The A-AFMA challenge was part of ISBI 2021, with the workshop taking place on April 13, 2021. We are no longer accepting submissions but are busy working on the next stage of the A-AFMA Challenge, which will be running in 2022.
Thank you to all the participants and congratulations to the winning teams:
Task 2 Localization:
1st DEER-AI
2nd MUSIC_SZU
3rd DEBUT_KELE
***
The A-AFMA Challenge Workshop is on 13th April, 1.30pm - 3.00pm (CET)¶
Workshop timetable
- Welcome
- Clinical context of amniotic fluid measurement
- The A-AFMA Challenge tasks
- Algorithm presentation: Task 1 winning team
- Algorithm presentation: Task 2 winning team
- Algorithm presentation: Chair’s choice winning team
- Analysis of results from different metrics
- Discussion
Introduction to the Challenge video¶
The aim of this task is to automatically predict two landmark coordinates within a (given) specified frame of an ultrasound video.
These coordinates are used to calculate a measure of the amount of amniotic fluid surrounding a fetus in-utero, called the maximum vertical pocket (MVP).
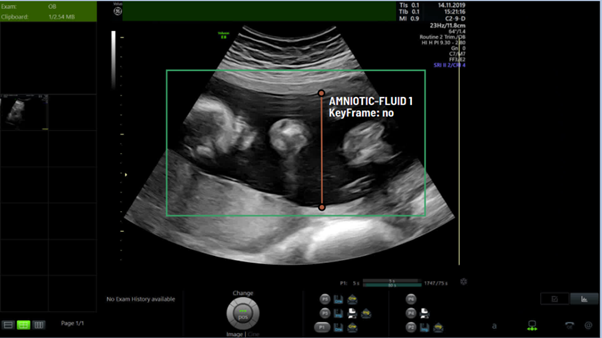
Figure 1: In this US frame, the ends of the orange line are the MVP landmarks within a bounding-box indicating amniotic fluid.
Clinically, an MVP measurement is made by drawing a vertical line perpendicular to the bottom of the frame (see Figure 1). A measurable pool of fluid should only contain amniotic fluid and not extend through the umbilical cord or fetus i.e. the line should only be drawn through a black area. The measurement should start at the anterior uterine wall/placental edge and extend down to the next solid area it reaches (which may be the fetus, placenta or posterior uterine wall). The aim is to measure the largest vertical pool and so in some circumstances this may mean the measurement starts/ends at a portion of cord/fetal part if this would provide the deepest measurement.
The ultrasound image in this task is taken from an ultrasound video recorded during a prenatal scan. The video was made up of a single sweep of the ultrasound probe over the maternal abdomen. Each image for the task will contain amniotic fluid and the maternal bladder as well as other anatomies (Figure 2). The specified image frame has been identified by the annotator as a good frame for measuring the MVP.

Figure 2: Example of a key frame for MVP measurement. The orange bounding-box indicates amniotic fluid, the green one indicates maternal bladder
Task¶
The aim of this task is to predict the location of the points that would be at each end of this line (the ‘landmark’ coordinates). The coordinates selected by the annotators are the ground truth for this task, and the challenge is to predict the coordinates of each point. The automated algorithms should be optimized to reduce the mean-square-error (MSE) of coordinates between the predicted landmarks and the ground-truth ones.
Evaluation¶
The evaluation measure is the average of the RMSE(Root Mean Squared Error) between the predicted and ground-truth landmark coordinates and the RMSE of the computed MVP length in pixels.